At the 2022 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR) this week, Adobe has co-authored a total of 48 papers, including 13 oral papers and 35 poster papers, plus 6 workshop papers.
Adobe authors have also contributed to the conference in many other ways, including co-organizing several workshops, area chairing, and reviewing papers.
Nearly all these papers are the result of research internships or other collaborations with university students and faculty. For those interested, please check out Adobe Research’s careers page to learn more about internships and full-time career opportunities.
Here are Adobe’s contributions to CVPR 2022.
Oral papers
BokehMe: When Neural Rendering Meets Classical Rendering
Juewen Peng, Zhiguo Cao, Xianrui Luo, Hao Lu, Ke Xian, Jianming Zhang
Ensembling Off-the-shelf Models for GAN Training
Nupur Kumari, Richard Zhang, Eli Shechtman, Jun-Yan Zhu
FaceFormer: Speech-Driven 3D Facial Animation with Transformers
Yingruo Fan, Zhaojiang Lin, Jun Saito, Wenping Wang, Taku Komura
GAN-Supervised Dense Visual Alignment
William Peebles Jun-Yan Zhu, Richard Zhang, Antonio Torralba, Alexei Efros, Eli Shechtman
Best Paper Finalist
IRON: Inverse Rendering by Optimizing Neural SDFs and Materials from Photometric Images
Kai Zhang, Fujun Luan, Zhengqi Li, Noah Snavely
MAT: Mask-Aware Transformer for Large Hole Image Inpainting
Wenbo Li, Zhe Lin, Kun Zhou, Lu Qi, Yi Wang, Jiaya Jia
NeRFusion: Fusing Radiance Fields for Large-Scale Scene Reconstruction
Xiaoshuai Zhang, Sai Bi, Kalyan Sunkavalli, Hao Su, Zexiang Xu
Point-NeRF: Point-based Neural Radiance Fields
Qiangeng Xu, Zexiang Xu, Julien Philip, Sai Bi, Zhixin Shu, Kalyan Sunkavalli, Ulrich Neumann
StyleSDF: High-Resolution 3D-Consistent Image and Geometry Generation
Roy Or-El, Xuan Luo, Mengyi Shan, Eli Shechtman, Jeong Joon Park, Ira Kemelmacher-Shlizerman
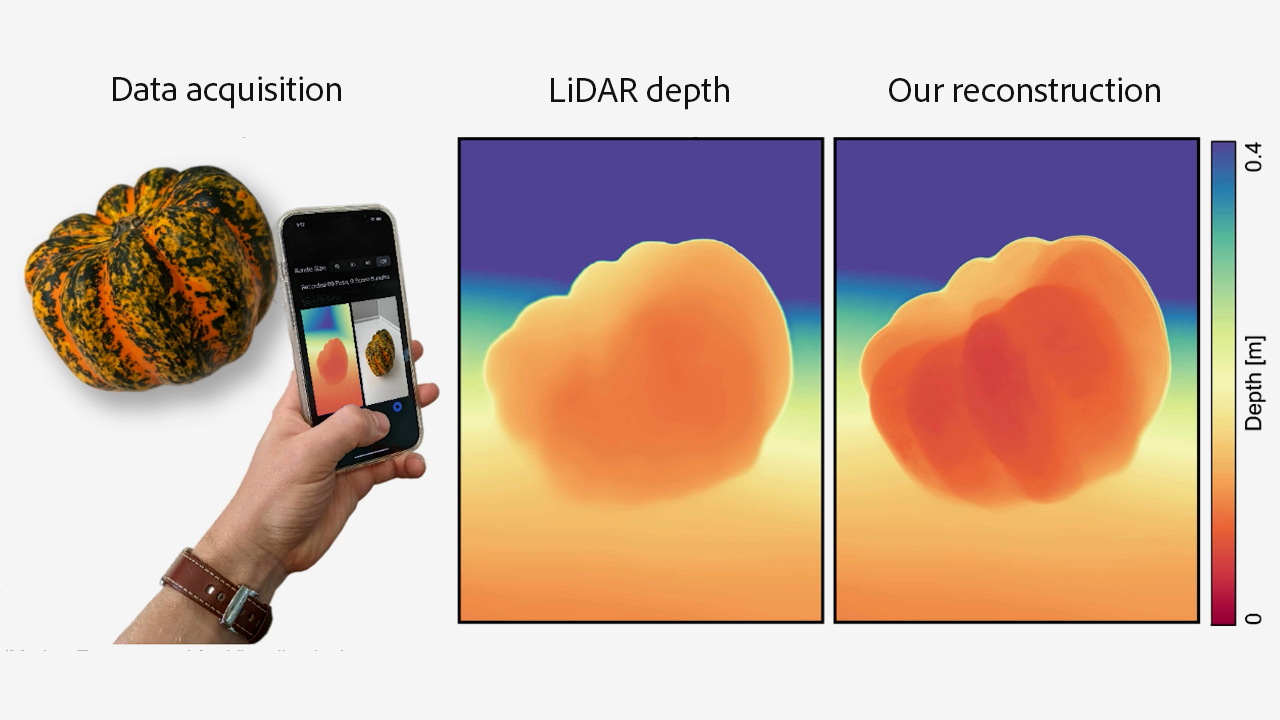
The Implicit Values of a Good Hand Shake: Handheld Multi-Frame Neural Depth Refinement
Ilya Chugunov, Yuxuan Zhang, Zhihao Xia, Xuaner (Cecilia) Zhang, Jiawen Chen, Felix Heide
Towards Layer-wise Image Vectorization
Xu Ma, Yuqian Zhou, Xingqian Xu, Bin Sun, Valerii Filev, Nikita Orlov, Yun Fu, Humphrey Shi
vCLIMB: A Novel Video Class Incremental Learning Benchmark
Andrés Villa, Kumail Alhamoud, Juan León Alcázar, Fabian Caba Heilbron, Victor Escorcia, Bernard Ghanem
VISOLO: Grid-Based Space-Time Aggregation for Efficient Online Video Instance Segmentation
Su Ho Han, Sukjun Hwang, Seoung Wug Oh, Yeonchool Park, Hyunwoo Kim, Min-Jung Kim, Seon Joo Kim
Poster papers
APES: Articulated Part Extraction from Sprite Sheets
Zhan Xu, Matthew Fisher, Yang Zhou, Deepali Aneja, Rushikesh Dudhat, Li Yi, Evangelos Kalogerakis
Audio-driven Neural Gesture Reenactment with Video Motion Graphs
Yang Zhou; Jimei Yang; Dingzeyu Li; Jun Saito; Deepali Aneja; Evangelos Kalogerakis
Boosting Robustness of Image Matting with Context Assembling and Strong Data Augmentation
Yutong Dai, Brian Price, He Zhang, Chunhua Shen
Cannot See the Forest for the Trees: Aggregating Multiple Viewpoints to Better Classify Objects in Videos
Sukjun Hwang, Miran Heo, Seoung Wug Oh, Seon Joo Kim
Controllable Animation of Fluid Elements in Still Images
Aniruddha Mahapatra, Kuldeep Kulkarni
Cross Modal Retrieval with Querybank Normalisation
Simion-Vlad Bogolin, Ioana Croitoru, Hailin Jin, Yang Liu, Samuel Albanie
EI-CLIP: Entity-Aware Interventional Contrastive Learning for E-Commerce Cross-Modal Retrieval
Haoyu Ma, Handong Zhao, Zhe Lin, Ajinkya Kale, Zhangyang Wang, Tong Yu, Jiuxiang Gu, Sunav Choudhary, Xiaohui Xie
Estimating Example Difficulty using Variance of Gradients
Chirag Agarwal, Daniel D’souza, Sara Hooker
Fairness-aware Adversarial Perturbation Towards Bias Mitigation for Deployed Deep Models
Zhibo Wang, Xiaowei Dong, Henry Xue, Zhifei Zhang, Weifeng Chiu, Tao Wei, Kui Ren
Focal length and object pose estimation via render and compare
Georgy Ponimatkin, Yann Labbé, Bryan Russell, Mathieu Aubry, Josef Sivic
Generalizing Interactive Backpropagating Refinement for Dense Prediction Networks
Fanqing Lin, Brian Price, Tony Martinez
GIRAFFE HD: A High-Resolution 3D-aware Generative Model
Yang Xue, Yuheng Li, Krishna Kumar Singh, Yong Jae
GLASS: Geometric Latent Augmentation for Shape Spaces
Sanjeev Muralikrishnan, Siddhartha Chaudhuri, Noam Aigerman, Vladimir Kim, Matthew Fisher, Niloy Mitra
High Quality Segmentation for Ultra High-resolution Images
Tiancheng Shen, Yuechen Zhang, Lu Qi, Jason Kuen, Xingyu Xie, Jianlong Wu, Zhe Lin, Jiaya Jia
InsetGAN for Full-Body Image Generation
Anna Frühstück, Krishna Kumar Singh, Eli Shechtman, Niloy Mitra, Peter Wonka, Jingwan Lu
It’s Time for Artistic Correspondence in Music and Video
Dídac Surís, Carl Vondrick, Bryan Russell, Justin Salamon
Layered Depth Refinement with Mask Guidance
Soo Ye Kim, Jianming Zhang, Simon Niklaus, Yifei Fan, Simon Chen, Zhe Lin, Munchurl Kim
Learning Motion-Dependent Appearance for High-Fidelity Rendering of Dynamic Humans from a Single Camera
Jae Shin Yoon, Duygu Ceylan, Tuanfeng Wang, Jingwan Lu, Jimei Yang, Zhixin Shu, Hyun Soo Park
Lite Vision Transformer with Enhanced Self-Attention
Chenglin Yang, Yilin Wang, Jianming Zhang, He Zhang, Zijun Wei, Zhe Lin, Alan Yuille
MAD: A Scalable Dataset for Language Grounding in Videos from Movie Audio Descriptions
Mattia Soldan, Alejandro Pardo, Juan León Alcázar, Fabian Caba Heilbron, Chen Zhao, Silvio Giancola, Bernard Ghanem
Many-to-many Splatting for Efficient Video Frame Interpolation
Ping Hu, Simon Niklaus, Stan Sclaroff, Kate Saenko
Neural Convolutional Surfaces
Luca Morreale, Noam Aigerman, Paul Guerrero, Vladimir Kim, Niloy Mitra
Neural Volumetric Object Selection
Zhongzheng Ren, Aseem Agarwala, Bryan Russell, Alexander Schwing, Oliver Wang
Neural Shape Mating: Self-Supervised Object Assembly with Adversarial Shape Priors
Yun-Chun Chen, Haoda Li, Dylan Turpin, Alec Jacobson, Animesh Garg
On Aliased Resizing and Surprising Subtleties in GAN Evaluation
Gaurav Parmar, Richard Zhang, Jun-Yan Zhu
Open-Vocabulary Instance Segmentation via Robust Cross-Modal Pseudo-Labeling
Dat Huynh, Jason Kuen, Zhe Lin, Jiuxiang Gu, Ehsan Elhamifar
Per-Clip Video Object Segmentation
Kwanyong Park, Sanghyun Woo, Seoung Wug Oh, In So Kweon, Joon-Young Lee
PhotoScene: Physically-Based Material and Lighting Transfer for Indoor Scenes
Yu-Ying Yeh, Zhengqin Li, Yannick Hold-Geoffroy, Rui Zhu, Zexiang Xu, Miloš Hašan, Kalyan Sunkavalli, Manmohan Chandraker
RigNeRF: Fully Controllable Neural 3D Portraits
ShahRukh Athar, Zexiang Xu, Kalyan Sunkavalli, Eli Shechtman, Zhixin Shu
ShapeFormer: Transformer-based Shape Completion via Sparse Representation
Xingguang Yan, Liqiang Lin, Niloy Mitra, Dani Lischinski, Danny Cohen-Or, Hui Huang
SketchEdit: Mask-Free Local Image Manipulation with Partial Sketches
Yu Zeng, Zhe Lin, Vishal M. Patel
Spatially-Adaptive Multilayer Selection for GAN Inversion and Editing
Gaurav Parmar, Yijun Li, Jingwan Lu, Richard Zhang, Jun-Yan Zhu, Krishna Kumar Singh
Towards Language-Free Training for Text-to-Image Generation
Yufan Zhou, Ruiyi Zhang, Changyou Chen, Chunyuan Li, Chris Tensmeyer, Tong Yu, Jiuxiang Gu, Jinhui Xu, Tong Sun
Unsupervised Learning of De-biased Representation with Pseudo-bias Attribute
Seonguk Seo, Joon-Young Lee, Bohyung Han
Workshop papers
ARIA: Adversarially Robust Image Attribution for Content Provenance
Maksym Andriushchenko, Xiaoyang Rebecca Li, Geoffrey Oxholm, Thomas Gittings, Tu Bui, Nicolas Flammarion, John Collomosse
Presented at Workshop on Media Forensics
Integrating Pose and Mask Predictions for Multi-person in Videos
Miran Heo, Sukjun Hwang, Seoung Wug Oh, Joon-Young Lee, Seon Joo Kim
Presented at Efficient Deep Learning for Computer Vision Workshop
MonoTrack: Shuttle trajectory reconstruction from monocular badminton video
Paul Liu, Jui-Hsien Wang
Presented at Workshop on Computer Vision in Sports
The Best of Both Worlds: Combining Model-based and Nonparametric Approaches for 3D Human Body Estimation
Zhe Wang, Jimei Yang, Charless Fowlkes
Presented at Workshop and Competition on Affective Behavior Analysis in-the-wild
User-Guided Variable Rate Learned Image Compression
Rushil Gupta, Suryateja BV, Nikhil Kapoor, Rajat Jaiswal, Sharmila Reddy Nangi, Kuldeep Kulkarni
Presented at Challenge and Workshop on Learned Image Compression
Video-ReTime: Learning Temporally Varying Speediness for Time Remapping
Simon Jenni, Markus Woodson, Fabian Caba Heilbron
Presented at Workshop: AI for Content Creation
Workshop co-organizers
AI for Content Creation Workshop
Cynthia Lu
ActivityNet Workshop
Fabian Caba Heilbron
Sketch-oriented Deep Learning
John Collomosse
Invited workshop talks
AI for Content Creation Workshop
Richard Zhang, Dugyu Ceylan
ActivityNet Workshop
Fabian Caba Heilbron
Holistic Video Understanding workshop
Vishy Swaminathan
LatinX in AI Workshop
Luis Figueroa, Matheus Gadelha
New Trends in Image Restoration and Enhancement Workshop
Richard Zhang