We all experience the world in three dimensions, but creating digital 3D models to represent that experience has been extraordinarily difficult. The work requires years of specialized training, access to complex tools, lots of time, and a huge collection of images as raw materials. But now, the Adobe Research team has developed new technology that’s making it as easy to create in 3D as it is in 2D. Users can also easily use their 3D content for 2D designs.
“If you want to create in 2D, you can take a photo, draw a figure, or use a text prompt in Firefly. Our goal was to provide this kind of capacity for everyone who wants to generate their own 3D content,” explains Research Scientist Hao Tan, a member of the team behind the new Text to 3D feature that’s now available in Adobe Substance Viewer and integrated into Photoshop as a plugin.
The Text to 3D feature allows users to create a 3D model based on a simple text input. Users can describe an object—perhaps a rainbow unicorn or an ice cream sundae with a cherry on top—and the tool generates it in seconds. Once a 3D model is generated, a user can rotate and view the model from any direction.
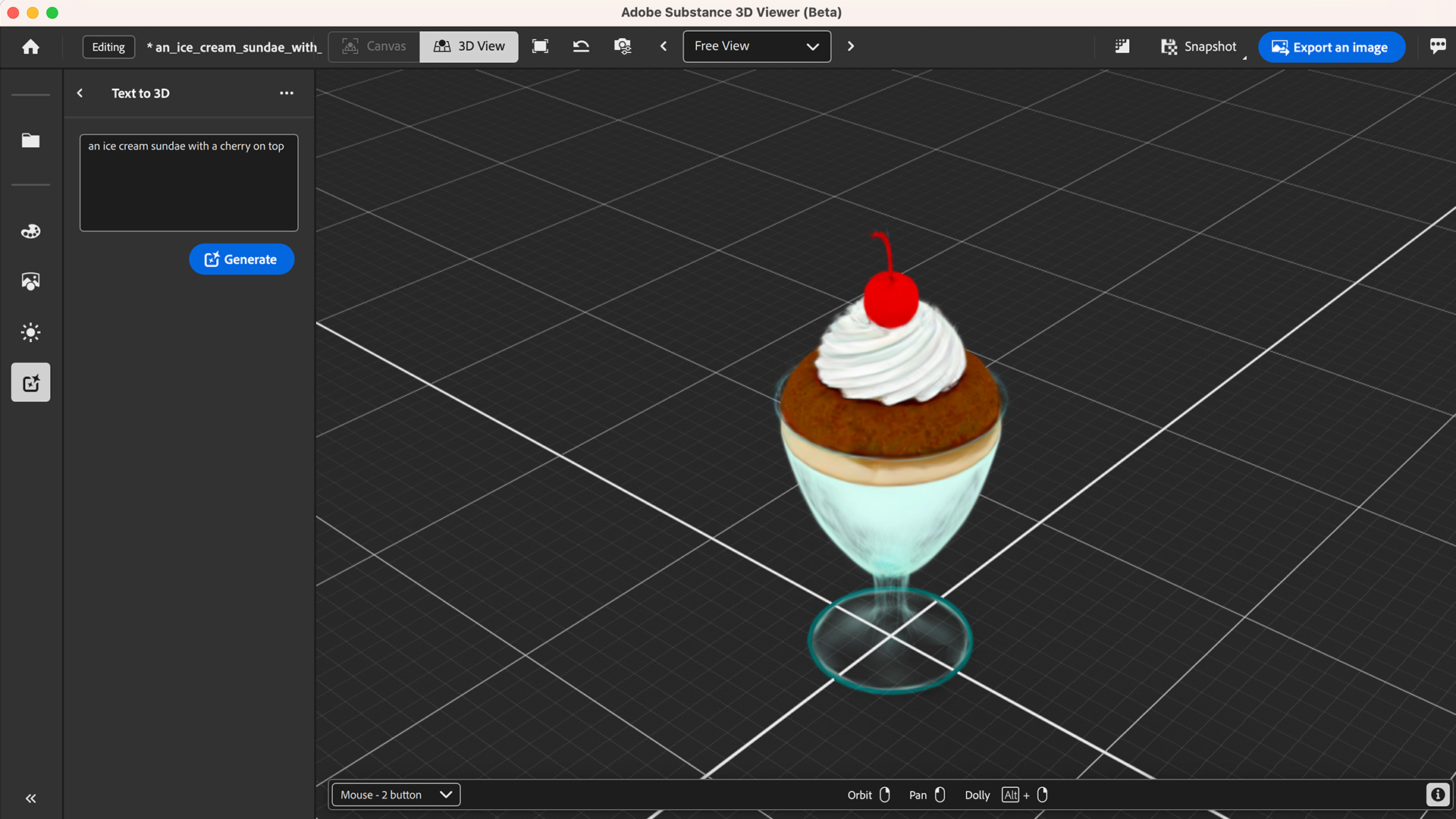
“A 3D model has the flexibility to let users get the exact angle and viewpoint they want, which gives people two very powerful workflows. They can go from text to creating in 3D, or they can position 3D models just the way they want them for a design in 2D,” says Principal Scientist Kalyan Sunkavalli, who leads the group that developed the new feature. “Professionals can also use this feature to quickly create prototypes and more complex 3D models,” adds Research Scientist Sai Bi.
The technology breakthroughs behind Text to 3D
The research behind the Text to 3D feature began with a classic computer graphics question: How can you reconstruct 3D from 2D images? “It’s a hard problem because the world is 3D, but we take photographs that compress that 3D information into 2D images,” explains Sunkavalli. The traditional approach in computer graphics and computer vision has been to start with many 2D images of an object or scene, find the points where they intersect, and then use that information to figure out where things are in space so you can reconstruct the 3D object.
Two recent advances, which grew out of developments in AI, helped set the stage for the new approach that powers Text to 3D. First, researchers began to think about different ways to represent 3D models. Traditional approaches use a 3D mesh, which is a collection of triangles with colors and textures on top, arranged to represent the surface of an object. But new approaches, known as NeRFs (neural radiance fields) and Gaussian splatting, represent color and light at any point in space. These methods enable the creation of photorealistic 3D models that can even capture the kinds of softer, fuzzier textures—like fur or leaves on tree branches—that are notoriously difficult to represent with a traditional 3D mesh. The new representations were also more compatible with AI models, but they still required hundreds of images and an expensive, complex optimization process to create photorealistic 3D objects.
The second development happened as people began training AI models with lots more 3D data, which allowed the AI models to begin filling in the information that’s needed for 3D representations—but the architecture of the models was still a constraint.
“We were seeing so much progress in generative AI for 2D and language, but it still wasn’t clear what to do on the 3D side. Things just hadn’t caught up,” remembers Sunkavalli.
That’s where the Adobe Research team came in. “We realized that if your input is 2D images and your output is the 3D representation, there is a mismatch between modalities. There are a lot of models that go from images to images or text to text. But 2D to 3D is hard to bridge. So our breakthrough was when we discovered that transformers, which are the networks that underpin all LLMs (large language models), are great for bridging modalities. You can train transformers to take images, or patches of images, and turn them into tokens in the same way that LLMs convert words into tokens. The transformer processes a string of image tokens and produces new tokens that we can arrange to build a 3D representation. Once you have this, it’s a really powerful thing—it’s an architecture that scales well, and as you add more data, it gets more powerful,” explains Sunkavalli. The team recently published their discoveries in several papers about large reconstruction models for single images to 3D, 3D Gaussian splatting, and high-quality mesh.
From there, the Adobe Research team used their discovery to build technology that can generate photorealistic 3D representations based on a single image, or a sparse set of images, rather than hundreds of images.
But there was one more step to get to 3D model generation from text prompts: They needed to tap into the Firefly generative model, which creates 2D images from text prompts, and tweak it to create multiple views for 3D reconstructions.
With all the pieces in place, the team had the basis for the new Text to 3D feature. It allows users to simply type in a text prompt to generate a 3D model in seconds. In addition, a pipeline was introduced to provide a traditional mesh-based 3D model alongside the Gaussian Splat version, giving users full control over the type of content they want to generate.

What’s next for Text to 3D?
The Adobe Research team is already working on the future of generative 3D tools. They want to continue to improve the quality of the 3D models, and they’re dreaming of even more possibilities.
Research Scientist Kai Zhang is thinking about the power of memories captured in 3D. “Photos are a 2D projection of our 3D world that allow you to store a moment you care about. With 3D technology, we could fully immerse ourselves back in that moment. You can imagine it as a way to bring people together,” he says.
“Our North Star is world building,” Sunkavalli adds. “It’s not just about single objects, it’s about building entire worlds that people can interact with. This is going to help people create very powerful content.”
Wondering what else is happening inside Adobe Research? Check out our latest news here.