A Differentiable Perceptual Audio Metric Learned from Just Noticeable Differences
Interspeech 2020
Publication date: October 26, 2020
Pranay Manocha, Adam Finkelstein, Richard Zhang, Nicholas J. Bryan, Gautham Mysore, Zeyu Jin
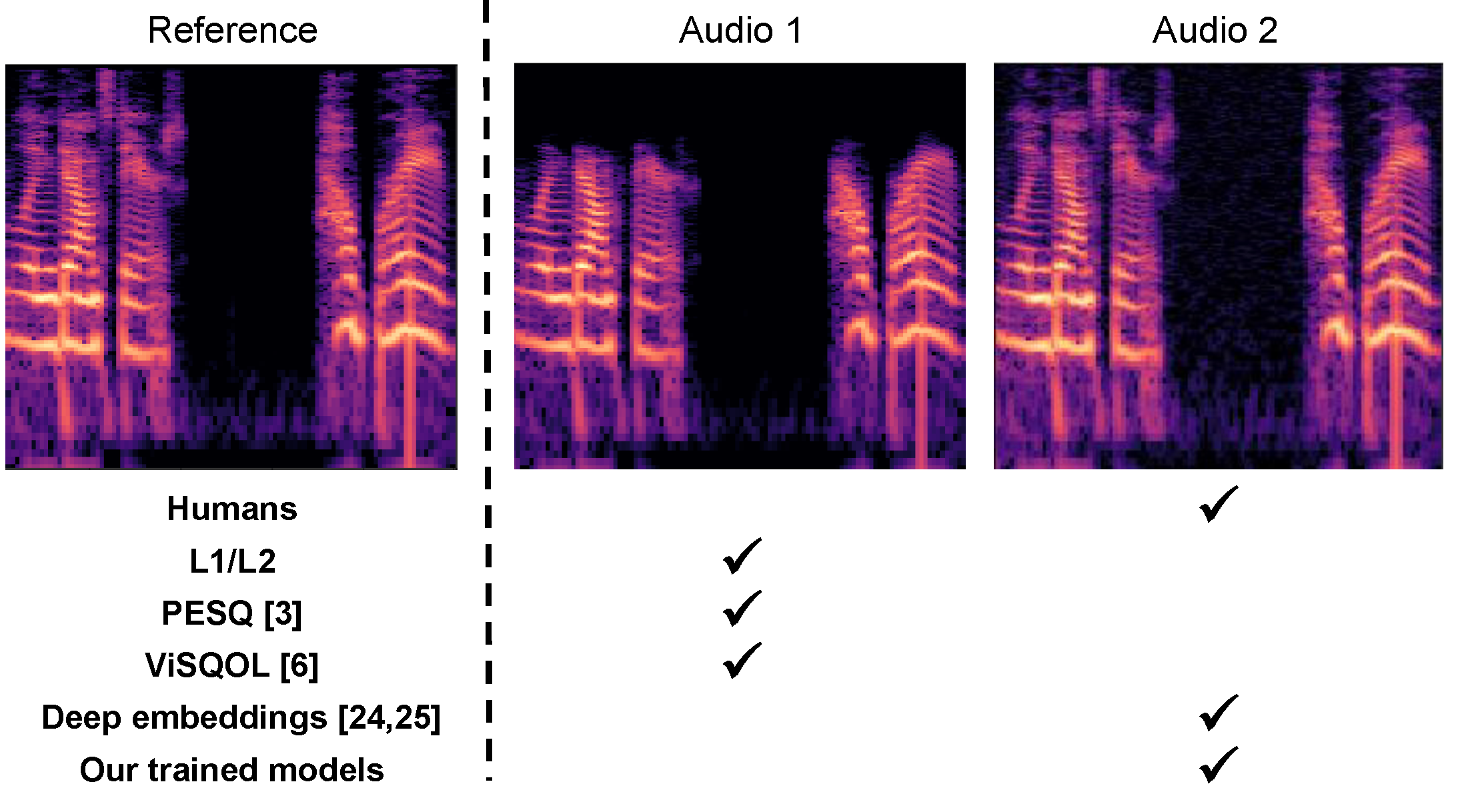
Many audio processing tasks require perceptual assessment. The ''gold standard'' of obtaining human judgments is time-consuming, expensive, and cannot be used as an optimization criterion. On the other hand, automated metrics are efficient to compute but often correlate poorly with human judgment, particularly for audio differences at the threshold of human detection. In this work, we construct a metric by fitting a deep neural network to a new large dataset of crowdsourced human judgments. Subjects are prompted to answer a straightforward, objective question: are two recordings identical or not? These pairs are algorithmically generated under a variety of perturbations, including noise, reverb, and compression artifacts; the perturbation space is probed with the goal of efficiently identifying the just-noticeable difference (JND) level of the subject. We show that the resulting learned metric is well-calibrated with human judgments, outperforming baseline methods. Since it is a deep network, the metric is differentiable, making it suitable as a loss function for other tasks. Thus, simply replacing an existing loss (e.g., deep feature loss) with our metric yields significant improvement in a denoising network, as measured by subjective pairwise comparison.
Learn More