Don’t Separate, Learn to Remix: End-to-End Neural Remixing with Joint Optimization
IEEE International Conference on Acoustics, Speech, and Signal Processing
Publication date: May 22, 2022
Haici Yang, Shivani Firodiya, Nicholas J. Bryan, Minje Kim
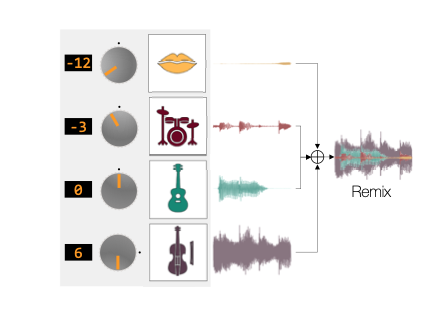
The task of manipulating the level and/or effects of individual instruments to recompose a mixture of recordings, or remixing, is common across a variety of applications such as music production, audio-visual post-production, podcasts, and more. This process, however, traditionally requires access to individual source recordings, restricting the creative process. To work around this, source separation algorithms can separate a mixture into its respective components. Then, a user can adjust their levels and mix them back together. This two-step approach, however, still suffers from audible artifacts and motivates further work. In this work, we learn to remix music directly by re-purposing Conv-TasNet, a well-known source separation model, into two neural remixing architectures. To do this, we use an explicit loss term that directly measures remix quality and jointly optimize it with a separation loss. We evaluate our methods using the Slakh and MUSDB18 datasets and report remixing performance as well as the impact on source separation as a byproduct. Our results suggest that learning-to-remix significantly outperforms a strong separation baseline and is particularly useful for small volume changes.
Learn More