Improving cross-modal attention via object detection
NeurIPS 2022 Workshop on All Things Attention
Publication date: December 2, 2022
Yongil Kim, Yerin Hwang, David Seunghyun Yoon, Hyeongu Yun, Kyomin Jung
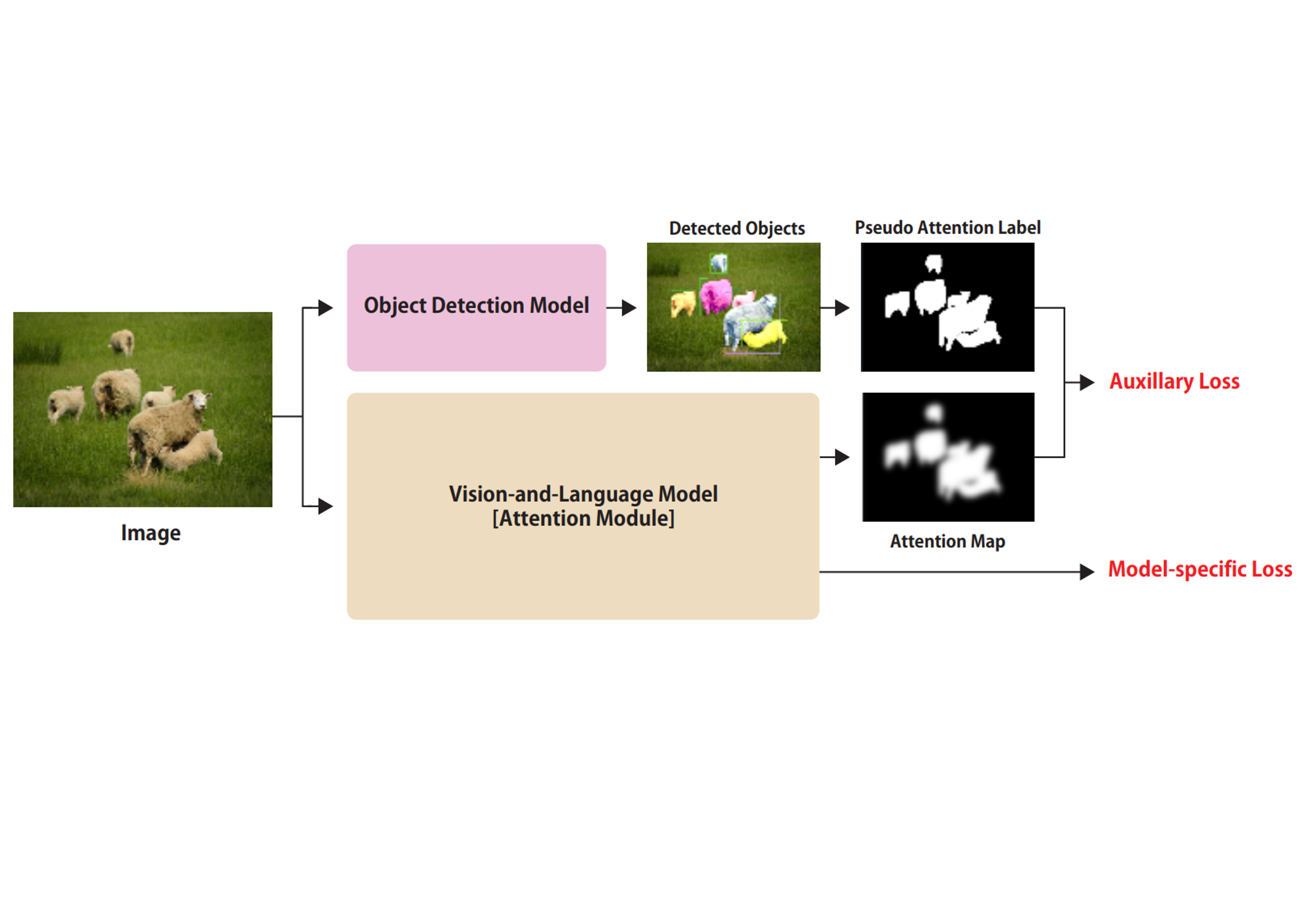
Cross-modal attention is widely used in multimodal learning to fuse information from two modalities. However, most existing models only assimilate cross-modal attention indirectly by relying on end-to-end learning and do not directly improve the attention mechanisms. In this paper, we propose a methodology for directly enhancing cross-modal attention by utilizing object-detection models for vision-and-language tasks that deal with image and text information. We used the mask of the detected objects obtained by the detection model as a pseudo label, and we added a loss between the attention map of the multimodal learning model and the pseudo label. The proposed methodology drastically improves the performance of the baseline model across all performance metrics in various popular datasets for the image-captioning task. Moreover, our highly scalable methodology can be applied to any multimodal task in terms of vision-and-language.