Simple Questions Generate Named Entity Recognition Datasets
EMNLP 2022
Publication date: December 11, 2022
Hyunjae Kim, Jaehyo Yoo, David Seunghyun Yoon, Jinhyuk Lee, Jaewoo Kang
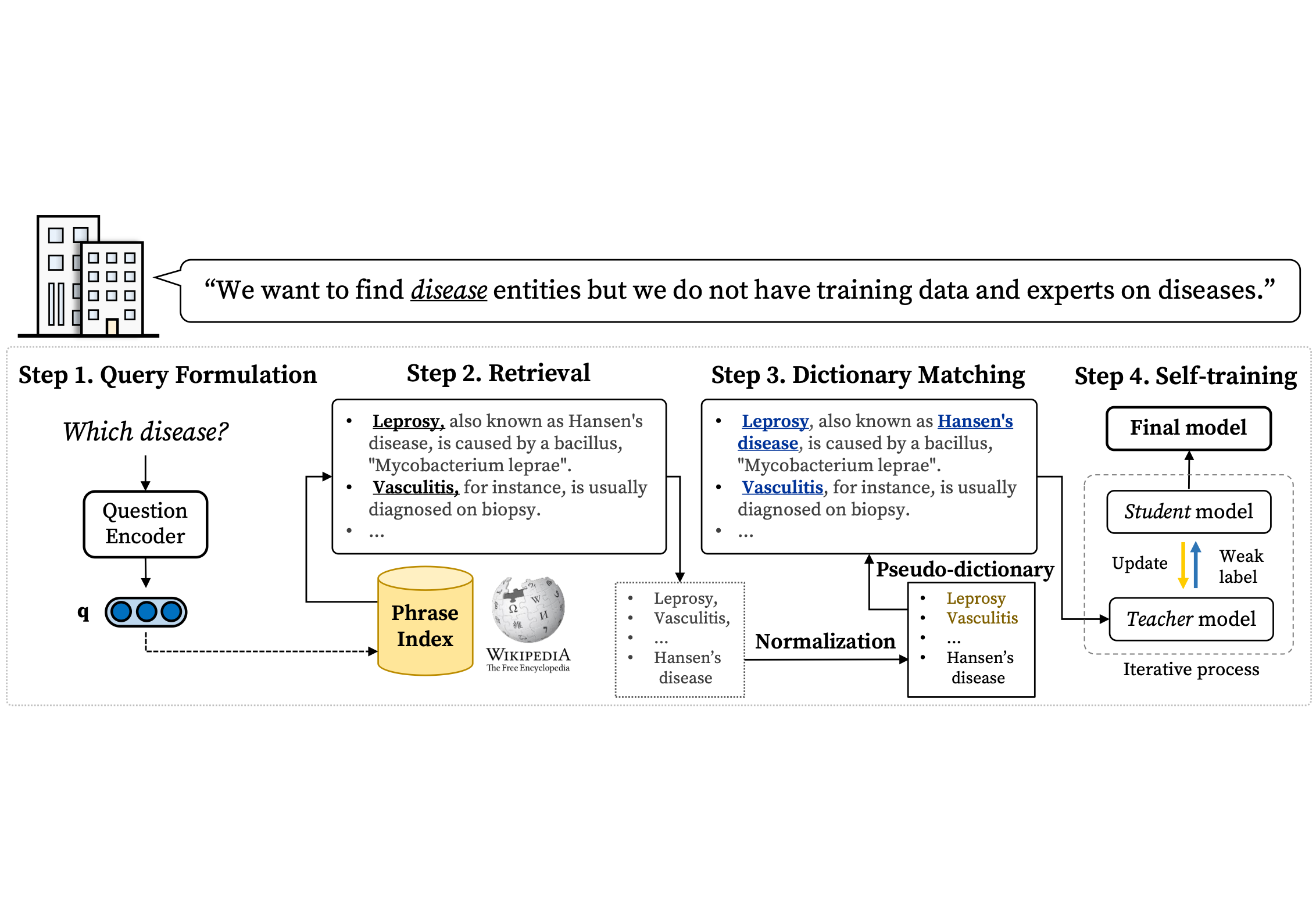
Named entity recognition (NER) is a task of extracting named entities of specific types from text. Current NER models often rely on human-annotated datasets requiring the vast engagement of professional knowledge on the target domain and entities. This work introduces an ask-to-generate approach, which automatically generates NER datasets by asking simple natural language questions that reflect the needs for entity types (e.g., “Which disease?”) to an open-domain question answering system. Without using any in-domain resources (i.e., training sentences, labels, or in-domain dictionaries), our models solely trained on our generated datasets largely outperform previous weakly supervised models on six NER benchmarks across four different domains. Surprisingly, on NCBI-disease, our model achieves 75.5 F1 score and even outperforms the previous best weakly supervised model by 4.1 F1 score, which utilizes a rich in-domain dictionary provided by domain experts. Formulating the needs of NER with natural language also allows us to build NER models for fine-grained entity types such as Award, where our model even outperforms fully supervised models. On three few-shot NER benchmarks, our model achieves new state-of-the-art performance.
Learn More