Understanding News Thumbnail Representativeness by Counterfactual Text-Guided Contrastive Language-Image Pretraining
ACL 2024 Findings
Publication date: August 12, 2024
Yejun Yoon, David Seunghyun Yoon, Kunwoo Park
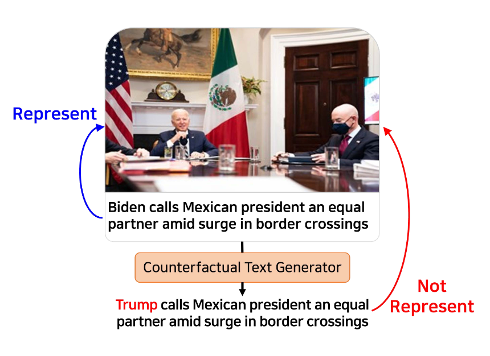
This paper delves into the critical challenge of understanding the representativeness of news thumbnail images, which often serve as the first visual engagement for readers when an article is disseminated on social media. We focus on whether a news image represents the main subject discussed in the news text. To serve the challenge, we introduce NEWSTT, a manually annotated dataset of news thumbnail image and text pairs. We found that pretrained vision and language models, such as CLIP and BLIP-2, struggle with this task. Since news subjects frequently involve named entities or proper nouns, a pretrained model could not have the ability to match its visual and textual appearances. To fill the gap, we propose CFT-CLIP, a counter-factual text-guided contrastive language-image pretraining framework. We hypothesize that learning to contrast news text with its counter-factual, of which named entities are replaced, can enhance the cross-modal matching ability in the target task. Evaluation experiments using NewsTT show that CFT-CLIP outperforms the pretrained models, such as CLIP and BLIP-2.
Learn More